Ensemble: Scikit-learn and Keras

Hi All, in this blog I want to talk about ensemble methods. Before I go into the details I want to give an overview of what this is. Imagine you work for a big tech firm that specializes in machine learning and there is a very important task that you want to done perfectly. Ideally, as this is a big tech firm, there would be more than just one or two machine learning engineers working on this, you would have teams of engineers working on it.
Now imagine there are say five best models that work really well, now you can choose one of them and put in production or if you are a little risk averse as I am you would rather use all five models and take an average of them. Remember the premise was that this is an important task and you can run these models in parallel if you need to so the overhead of running five models is not that critical if this improves accuracy.
As you might have guessed this is what ensemble does. It takes an (weighted) average of a few models to come up the final answer and since this is running based on more than one model the accuracy usually improves.
Before I started this blog I was going to use just scikit-learn models but I realized there is very little help about how to use ensemble models that use both scikit-learn models and deep learning models from Keras. So I have decided to try using both of them and here is how to do it.
1. Dataset: Load the data set, no need for feature engineering here.
2. Build Models: Build both scikit-learn models and tensorflow keras models.
3. Fit Models: Train the models using scikit-learn fit method.
4. Evaluate Models: We check our models performances and ensemble model performance.
Dataset:
We use the inbuilt and readily available make moons dataset from scikit learn.
First, let’s look at how to load data. Since this is a in-built data set from scikit learn we just call the function from scikit-learn. You can read more about the data from here.
#Importsimport sklearn
from sklearn.datasets import make_moonsfrom sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score#Load data
X,y=make_moons(n_samples=500,noise=0.30,random_state=42)#Split test and train data
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=42)
Build Models:
log_clf = LogisticRegression(solver="lbfgs", random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=100, random_state=42)
svm_clf = SVC(gamma="scale", random_state=42,probability=True)# Keras Model
def build_nn():
model= Sequential([
Dense(50,activation='relu',input_shape=[2]),
Dense(1,activation='sigmoid')
]) model.compile(
optimizer='Adam',
loss='binary_crossentropy',
metrics=['accuracy']) return model
Till now there is nothing new as we plainly building models from scikit-learn and keras. Here comes the magic line that changes everything.
keras_clf = tf.keras.wrappers.scikit_learn.KerasClassifier(
build_nn,
epochs=500,
verbose=False)This one line wrapper call converts the keras model into a scikit-learn model that can be used for Hyperparameter tuning using grid search, Random search etc but it can also be used, as you guessed it, for ensemble methods.
Since this is a classifier we need one additional line to get this working.
keras_clf._estimator_type = "classifier"#https://stackoverflow.com/questions/59897096/votingclassifier-with-pipelines-as-estimators/59915844#59915844
Finally we define the voting classifier using the below code.
voting = VotingClassifier(
estimators=[('lr', log_clf),
('rf', rnd_clf),
('svc', svm_clf),
('keras',keras_clf)],
voting='soft',
flatten_transform=True)Fit Models:
With the VotingClassifer setup, now all we need to do is fit it on our train data.
voting.fit(X_train,y_train)
Evaluate Models:
Now the final test to see how the model performs on our test dataset.
for clf in (log_clf, rnd_clf, svm_clf, keras_clf, voting):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))This gives the below final results.
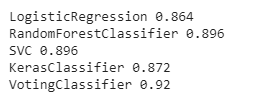
As you can see the VotingClassifier with an accuracy of 92% is much better than any individual model. All the code for this blog is here.
Before I end my blog, I want to take this opportunity to thank Aurelien Geron for his excellent book “Hands-on Machine Learning with Scikit-Learn, Keras & Tensorflow”. It has taught me a lot and I hope to keep sharing my experiments and thoughts. Hope you would find this blog useful.
Good luck !!!
References:
Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow by Aurelien Geron
